New & Notable

Bridging the digital defense gap: Why cybersecurity education matters more than ever
Dan Wilson | July 24, 2025 at 11:25 amTop Webinar

Recently Added
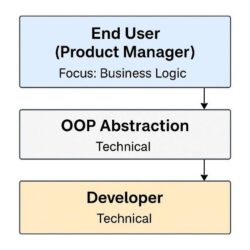
Empowering cybersecurity product managers with LangChain
Hrishitva Patel | August 5, 2025 at 4:39 pmIntroduction The cybersecurity landscape is experiencing unprecedented transformation as organizations scramble to integ...

How graph thinking empowers agentic AI
Jans Aasman | July 29, 2025 at 11:35 amAgentic AI systems are designed to adapt to new situations without requiring constant human intervention. These systems ...
Bridging the digital defense gap: Why cybersecurity education matters more than ever
Dan Wilson | July 24, 2025 at 11:25 amSince attending the RSA Convention 2025 in San Francisco, I’ve had much more to consider regarding the sanctity of our...

Data quality for unbiased results: Preventing AI-induced hallucinations
Robert Stanley | July 22, 2025 at 10:45 amArtificial Intelligence (AI) has revolutionized and will continue to transform many customer-facing industries. AI-power...

FinOps and the need for straight talk
Eric Ethridge | July 22, 2025 at 10:30 amFinOps is about bringing together leaders in business, technology, finance, and engineering to gain a clear understandin...
How to launch an AI startup in 2025
Vincent Granville | July 20, 2025 at 11:07 pmYou have plenty of experience. Maybe you are over 40, or fresh out of college, and you realize that there is no tech job...

How AI is transforming financial forecasting for SMBs and enterprises
Dan Wilson | July 15, 2025 at 2:57 pmPerspectives from various industries. Financial forecasting has long been a cornerstone of strategic planning, essential...

Why good data doesn’t guarantee good decisions
Lenard Lim | July 14, 2025 at 5:25 pmIt’s easy to assume that more data—or cleaner dashboards—will automatically lead to better decisions. But after wo...

How to architect a scalable data pipeline for HealthTech applications
Gaurav Belani | July 9, 2025 at 10:00 amHealthTech runs on data. From patient vitals and lab results to insurance claims and wearable device streams, there’s ...

Ethics-driven model auditing and bias mitigation
Shanthababu Pandian | July 7, 2025 at 3:06 pmIntroduction Artificial intelligence (AI) and machine learning (ML) systems are becoming increasingly integral to decisi...
New Videos

A/B Testing Pitfalls – Interview w/ Sumit Gupta @ Notion
Interview w/ Sumit Gupta – Business Intelligence Engineer at Notion In our latest episode of the AI Think Tank Podcast, I had the pleasure of sitting…

Davos World Economic Forum Annual Meeting Highlights 2025
Interview w/ Egle B. Thomas Each January, the serene snow-covered landscapes of Davos, Switzerland, transform into a global epicenter for dialogue on economics, technology, and…

A vision for the future of AI: Guest appearance on Think Future 1039
As someone who has spent years navigating the exciting and unpredictable currents of innovation, I recently had the privilege of joining Chris Kalaboukis on his show, Think Future.…
